What is a CAPTCHA in Web Scraping and How to Deal with It?
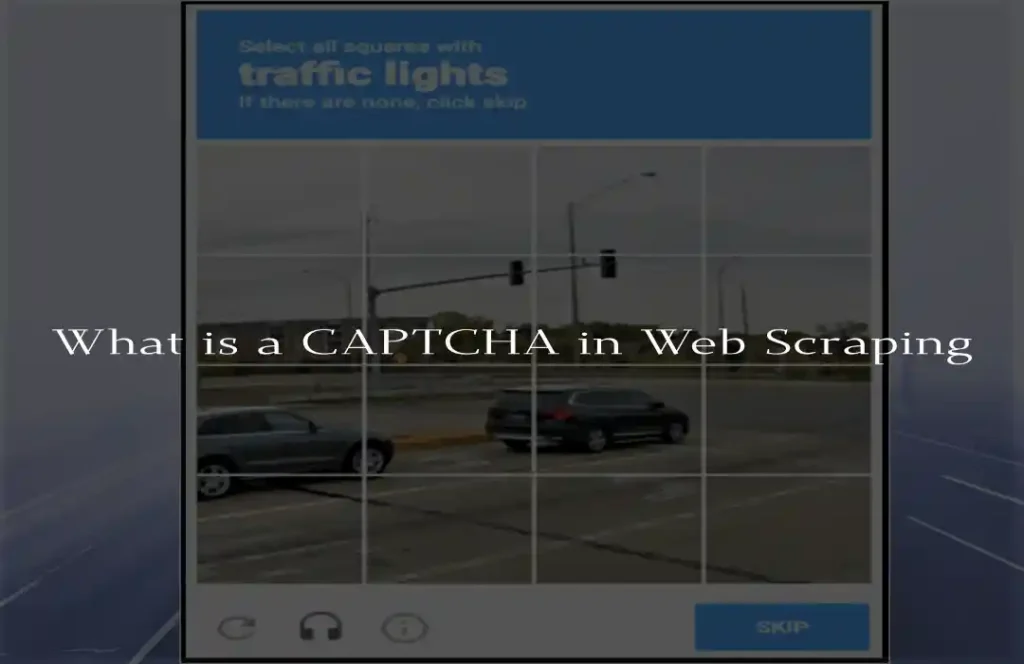
Web scraping can be a useful instrument for gaining details from web pages, however the most common issue people face when scraping is dealing CAPTCHAs. CAPTCHAs — which stand to mean “Completely automated public Turing test designed to differentiate computers and human beings Apart”–are created to shield sites from automated bots. While they are vital in ensuring the security of websites, they can also make it difficult for the extraction of data for legitimate reasons.
This guide examines the internet scraper CAPTCHAs are, how websites utilize them, and effective strategies to defeat these in a responsible and effective manner.
What is a CAPTCHA?
The CAPTCHA is a method that is designed to differentiate between the human user and the automated scripts. Most often, CAPTCHAs ask users to complete tasks that are difficult for robots to accomplish like:
- Recognizing objects in pictures (e.g., “select all the cars”)
- Typing distorted letters or numbers
- A box marked “I’m not a robot”
- Math problems that require basic understanding
They create obstacles that automated scraping software can be unable to overcome, shielding sites from bots, spam, or other fraudulent activities.
Why Websites Use CAPTCHAs
The primary purpose of CAPTCHAs is to secure websites and information. The reason they’re important is:
- Prevent Unauthorized Access
Websites utilize CAPTCHAs to stop automated robots from accessing their websites. This safeguards personal information of users and limits data access to authentic users.
- Data Integrity
CAPTCHAs help ensure that data that is on the website doesn’t get used in a massive way for misuse or theft of content or the creation of duplicate sites.
- Limit Resource Overload
Bots that are automated can overload the server by repeatedly asking for the same data. CAPTCHAs serve as a security measure by preventing server slowdowns due to bots.
- Protecting Intellectual Property
Businesses invest money in the creation of valuable material. CAPTCHAs block scraping without authorization of the content and ensure that the ownership of this content is protected.
If you are a web scraper who is performing legitimate jobs, a CAPTCHA can cause frustration. However, ethical and strategically-designed strategies can allow you to bypass the CAPTCHAs when scraping data falls within the legal limits.
What to do about the CAPTCHA During Web Scraping
These are actionable steps and strategies for dealing with CAPTCHA issues successfully:
1. Rotate Your IP Address
A lot of CAPTCHAs trigger by the fact that they see numerous requests coming from the same IP. Utilizing a proxy service to change your IP address every time you request a page can in avoiding the detection.
Actionable Tip:
- Utilize residential proxy products like Bright Data, ProxyMesh, or ScraperAPI for a similar experience that comes from actual users.
2. Adjust Request Rate and Patterns
If you send too many requests fast can result in an CAPTCHA. Impersonating human browsing behaviour through slowing your request can help you keep your profile hidden.
Actionable Tip:
- Introduce random delays between requests.
- Do not send requests with the same pattern.
3. Use CAPTCHA Solving Services
If you find that a CAPTCHA can’t be avoided completely Services such as 2Captcha or AntiCaptcha excel in the process of solving CAPTCHAs for the user. They rely on the human workforce or AI to complete CAPTCHA jobs quickly.
Actionable Tip:
- Integrate an API to solve CAPTCHAs directly into the workflow of your scraper.
4. Handle JavaScript-Based CAPTCHAs
A few more advanced CAPTCHAs including Google reCAPTCHA, are based on monitoring user behavior in the course of the course of. The CAPTCHAs may need running JavaScript as well as interacting with an online site dynamically.
Actionable Tip:
- Make use of web scraping tools that have an unidirectional browser, such as Puppeteer or Selenium that simulate actual browsing behaviour.
5. Leverage Machine Learning for Bypass Automation
To create more advanced configurations, machine learning algorithms are able to detect and resolve CAPTCHAs using image recognition or pattern recognition.
Actionable Tip:
- Software such as OpenCV or TensorFlow are able to help you build models that solve CAPTCHAs. Be cautious and ensure compliance with the legally-defined limitations.
6. Check for CAPTCHA-Free Data Options
Before making use of complex CAPTCHA bypass techniques, you should check for the possibility that the site provides an API. APIs typically offer a structured and authorized way to gain access to data, without activating CAPTCHAs.
Actionable Tip:
- Review the website’s manual for information on whether the API is accessible. Numerous websites provide access to APIs for moderate costs, or the cost of a small amount.
7. Works with ethical and Legal Methods
It’s important to stress that even though completing CAPTCHAs may be both technically and enjoyable, ethics and legal compliance must always guide your decisions. A lot of websites clearly state their conditions of service that prohibit scraping or resizing without permission.
Actionable Tip:
- Be sure that your scraping plan is in compliance to the local rules, including GDPR CCPA as well as your local laws like the Computer Fraud and Abuse Act (CFAA).
- If you can, request permission from the website’s owners prior to scraping.
CAPTCHAs and. Ethical Scraping
CAPTCHAs are a way to distinguish between responsible scraping of websites and encroaching on the website’s operation or its the terms of service. The most important thing is to prioritize moral and ethical practices.
- Know the reasons you’re using the data to make your decisions and be sure that it is in line with your legitimate objectives.
- Do not overload website servers, as it could cause disruption to the operation of their servers.
- Follow the rules of service and respect the rights of the website’s owner.
Web scraping should be able to bring value and not do harm.
Final Thoughts
CAPTCHAs are a fundamental component of scraping on the web. They are designed to safeguard sites from bots that are harmful however, they also can present a challenge to legitimate users as well as responsible scrapers. Utilizing strategic strategies, such as shifting IPs around, decreasing the rate of requests, or using CAPTCHA-solving software, you can tackle the challenges efficiently while remaining in compliance with legal and ethical standards.
If dealing with CAPTCHA obstacles feels daunting Consider working with the existing APIs or talking to experts to streamline the process of scraping web pages. By using the correct plan, you will be able to gather essential data for your business demands efficiently and responsibly.
Also Read: What is Salesloft